weekly-contest-322
A
Statement
Metadata
- Link: 回环句
- Difficulty: Easy
- Tag:
句子 是由单个空格分隔的一组单词,且不含前导或尾随空格。
- 例如,
"Hello World"、"HELLO"、"hello world hello world"都是符合要求的句子。
单词 仅 由大写和小写英文字母组成。且大写和小写字母会视作不同字符。
如果句子满足下述全部条件,则认为它是一个 回环句 :
- 单词的最后一个字符和下一个单词的第一个字符相等。
- 最后一个单词的最后一个字符和第一个单词的第一个字符相等。
例如,"leetcode exercises sound delightful"、"eetcode"、"leetcode eats soul" 都是回环句。然而,"Leetcode is cool"、"happy Leetcode"、"Leetcode" 和 "I like Leetcode" 都 不 是回环句。
给你一个字符串 sentence ,请你判断它是不是一个回环句。如果是,返回 true ;否则,返回 false 。
示例 1:
输入:sentence = "leetcode exercises sound delightful"
输出:true
解释:句子中的单词是 ["leetcode", "exercises", "sound", "delightful"] 。
- leetcode 的最后一个字符和 exercises 的第一个字符相等。
- exercises 的最后一个字符和 sound 的第一个字符相等。
- sound 的最后一个字符和 delightful 的第一个字符相等。
- delightful 的最后一个字符和 leetcode 的第一个字符相等。
这个句子是回环句。示例 2:
输入:sentence = "eetcode"
输出:true
解释:句子中的单词是 ["eetcode"] 。
- eetcode 的最后一个字符和 eetcode 的第一个字符相等。
这个句子是回环句。示例 3:
输入:sentence = "Leetcode is cool"
输出:false
解释:句子中的单词是 ["Leetcode", "is", "cool"] 。
- Leetcode 的最后一个字符和 is 的第一个字符 不 相等。
这个句子 不 是回环句。
提示:
1 <= sentence.length <= 500sentence仅由大小写英文字母和空格组成sentence中的单词由单个空格进行分隔- 不含任何前导或尾随空格
Metadata
- Link: Circular Sentence
- Difficulty: Easy
- Tag:
A sentence is a list of words that are separated by a single space with no leading or trailing spaces.
- For example,
"Hello World","HELLO","hello world hello world"are all sentences.
Words consist of only uppercase and lowercase English letters. Uppercase and lowercase English letters are considered different.
A sentence is circular if:
- The last character of a word is equal to the first character of the next word.
- The last character of the last word is equal to the first character of the first word.
For example, "leetcode exercises sound delightful", "eetcode", "leetcode eats soul" are all circular sentences. However, "Leetcode is cool", "happy Leetcode", "Leetcode" and "I like Leetcode" are not circular sentences.
Given a string sentence, return true if it is circular. Otherwise, return false.
Example 1:
Input: sentence = "leetcode exercises sound delightful"
Output: true
Explanation: The words in sentence are ["leetcode", "exercises", "sound", "delightful"].
- leetcode's last character is equal to exercises's first character.
- exercises's last character is equal to sound's first character.
- sound's last character is equal to delightful's first character.
- delightful's last character is equal to leetcode's first character.
The sentence is circular.Example 2:
Input: sentence = "eetcode"
Output: true
Explanation: The words in sentence are ["eetcode"].
- eetcode's last character is equal to eetcode's first character.
The sentence is circular.Example 3:
Input: sentence = "Leetcode is cool"
Output: false
Explanation: The words in sentence are ["Leetcode", "is", "cool"].
- Leetcode's last character is not equal to is's first character.
The sentence is not circular.
Constraints:
1 <= sentence.length <= 500sentenceconsist of only lowercase and uppercase English letters and spaces.- The words in
sentenceare separated by a single space. - There are no leading or trailing spaces.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
bool isCircularSentence(string s) {
int n = int(s.size());
for (int i = 1; i < n - 1; i++) {
if (s[i] == ' ') {
if (s[i - 1] != s[i + 1]) {
return false;
}
}
}
return s[0] == s.end()[-1];
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
B
Statement
Metadata
- Link: 划分技能点相等的团队
- Difficulty: Medium
- Tag:
给你一个正整数数组 skill ,数组长度为 偶数 n ,其中 skill[i] 表示第 i 个玩家的技能点。将所有玩家分成 n / 2 个 2 人团队,使每一个团队的技能点之和 相等 。
团队的 化学反应 等于团队中玩家的技能点 乘积 。
返回所有团队的 化学反应 之和,如果无法使每个团队的技能点之和相等,则返回 -1 。
示例 1:
输入:skill = [3,2,5,1,3,4]
输出:22
解释:
将玩家分成 3 个团队 (1, 5), (2, 4), (3, 3) ,每个团队的技能点之和都是 6 。
所有团队的化学反应之和是 1 * 5 + 2 * 4 + 3 * 3 = 5 + 8 + 9 = 22 。
示例 2:
输入:skill = [3,4]
输出:12
解释:
两个玩家形成一个团队,技能点之和是 7 。
团队的化学反应是 3 * 4 = 12 。
示例 3:
输入:skill = [1,1,2,3]
输出:-1
解释:
无法将玩家分成每个团队技能点都相等的若干个 2 人团队。
提示:
2 <= skill.length <= 105skill.length是偶数1 <= skill[i] <= 1000
Metadata
- Link: Divide Players Into Teams of Equal Skill
- Difficulty: Medium
- Tag:
You are given a positive integer array skill of even length n where skill[i] denotes the skill of the ith player. Divide the players into n / 2 teams of size 2 such that the total skill of each team is equal.
The chemistry of a team is equal to the product of the skills of the players on that team.
Return the sum of the chemistry of all the teams, or return -1 if there is no way to divide the players into teams such that the total skill of each team is equal.
Example 1:
Input: skill = [3,2,5,1,3,4]
Output: 22
Explanation:
Divide the players into the following teams: (1, 5), (2, 4), (3, 3), where each team has a total skill of 6.
The sum of the chemistry of all the teams is: 1 * 5 + 2 * 4 + 3 * 3 = 5 + 8 + 9 = 22.
Example 2:
Input: skill = [3,4]
Output: 12
Explanation:
The two players form a team with a total skill of 7.
The chemistry of the team is 3 * 4 = 12.
Example 3:
Input: skill = [1,1,2,3]
Output: -1
Explanation:
There is no way to divide the players into teams such that the total skill of each team is equal.
Constraints:
2 <= skill.length <= 105skill.lengthis even.1 <= skill[i] <= 1000
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
long long dividePlayers(vector<int> &skill) {
int sum = accumulate(all(skill), 0);
int n = int(skill.size());
int m = n / 2;
int need = sum / m;
sort(all(skill));
ll res = 0;
int r = n - 1;
for (int i = 0; i < r; i++, r--) {
if (skill[i] + skill[r] != need) {
return -1;
}
res += 1ll * skill[i] * skill[r];
}
return res;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
C
Statement
Metadata
- Link: 两个城市间路径的最小分数
- Difficulty: Medium
- Tag:
给你一个正整数 n ,表示总共有 n 个城市,城市从 1 到 n 编号。给你一个二维数组 roads ,其中 roads[i] = [ai, bi, distancei] 表示城市 ai 和 bi 之间有一条 双向 道路,道路距离为 distancei 。城市构成的图不一定是连通的。
两个城市之间一条路径的 分数 定义为这条路径中道路的 最小 距离。
城市 1 和城市 n 之间的所有路径的 最小 分数。
注意:
- 一条路径指的是两个城市之间的道路序列。
- 一条路径可以 多次 包含同一条道路,你也可以沿着路径多次到达城市
1和城市n。 - 测试数据保证城市
1和城市n之间 至少 有一条路径。
示例 1:
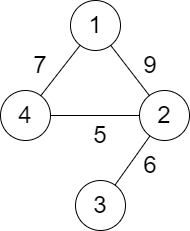
输入:n = 4, roads = [[1,2,9],[2,3,6],[2,4,5],[1,4,7]]
输出:5
解释:城市 1 到城市 4 的路径中,分数最小的一条为:1 -> 2 -> 4 。这条路径的分数是 min(9,5) = 5 。
不存在分数更小的路径。
示例 2:
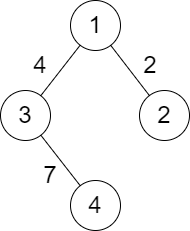
输入:n = 4, roads = [[1,2,2],[1,3,4],[3,4,7]]
输出:2
解释:城市 1 到城市 4 分数最小的路径是:1 -> 2 -> 1 -> 3 -> 4 。这条路径的分数是 min(2,2,4,7) = 2 。
提示:
2 <= n <= 1051 <= roads.length <= 105roads[i].length == 31 <= ai, bi <= nai != bi1 <= distancei <= 104- 不会有重复的边。
- 城市
1和城市n之间至少有一条路径。
Metadata
- Link: Minimum Score of a Path Between Two Cities
- Difficulty: Medium
- Tag:
You are given a positive integer n representing n cities numbered from 1 to n. You are also given a 2D array roads where roads[i] = [ai, bi, distancei] indicates that there is a bidirectional road between cities ai and bi with a distance equal to distancei. The cities graph is not necessarily connected.
The score of a path between two cities is defined as the minimum distance of a road in this path.
Return the minimum possible score of a path between cities 1 and n.
Note:
- A path is a sequence of roads between two cities.
- It is allowed for a path to contain the same road multiple times, and you can visit cities
1andnmultiple times along the path. - The test cases are generated such that there is at least one path between
1andn.
Example 1:
Input: n = 4, roads = [[1,2,9],[2,3,6],[2,4,5],[1,4,7]]
Output: 5
Explanation: The path from city 1 to 4 with the minimum score is: 1 -> 2 -> 4. The score of this path is min(9,5) = 5.
It can be shown that no other path has less score.
Example 2:
Input: n = 4, roads = [[1,2,2],[1,3,4],[3,4,7]]
Output: 2
Explanation: The path from city 1 to 4 with the minimum score is: 1 -> 2 -> 1 -> 3 -> 4. The score of this path is min(2,2,4,7) = 2.
Constraints:
2 <= n <= 1051 <= roads.length <= 105roads[i].length == 31 <= ai, bi <= nai != bi1 <= distancei <= 104- There are no repeated edges.
- There is at least one path between
1andn.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
const int INF = 0x3f3f3f3f;
class Solution {
public:
vector<vector<tuple<int, int>>> g{};
int n;
int bfs() {
int st = 1;
auto dis = vector<int>(n + 5, INF);
queue<int> q;
q.push(st);
while (!q.empty()) {
int u = q.front();
q.pop();
for (const auto &[v, d] : g[u]) {
int cur_dis = min(dis[u], d);
if (cur_dis < dis[v]) {
dis[v] = cur_dis;
q.push(v);
}
}
}
return dis[n];
}
int minScore(int n, vector<vector<int>> &roads) {
g.clear();
g = vector<vector<tuple<int, int>>>(n + 5, vector<tuple<int, int>>());
this->n = n;
for (const auto &r : roads) {
int u = r[0];
int v = r[1];
int d = r[2];
g[u].push_back(make_tuple(v, d));
g[v].push_back(make_tuple(u, d));
}
return bfs();
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif
D
Statement
Metadata
- Link: 将节点分成尽可能多的组
- Difficulty: Hard
- Tag:
给你一个正整数 n ,表示一个 无向 图中的节点数目,节点编号从 1 到 n 。
同时给你一个二维整数数组 edges ,其中 edges[i] = [ai, bi] 表示节点 ai 和 bi 之间有一条 双向 边。注意给定的图可能是不连通的。
请你将图划分为 m 个组(编号从 1 开始),满足以下要求:
- 图中每个节点都只属于一个组。
- 图中每条边连接的两个点
[ai, bi],如果ai属于编号为x的组,bi属于编号为y的组,那么|y - x| = 1。
请你返回最多可以将节点分为多少个组(也就是最大的 m )。如果没办法在给定条件下分组,请你返回 -1 。
示例 1:
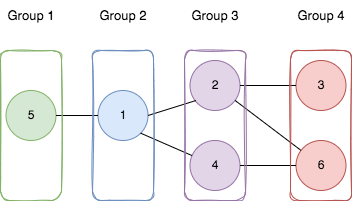
输入:n = 6, edges = [[1,2],[1,4],[1,5],[2,6],[2,3],[4,6]]
输出:4
解释:如上图所示,
- 节点 5 在第一个组。
- 节点 1 在第二个组。
- 节点 2 和节点 4 在第三个组。
- 节点 3 和节点 6 在第四个组。
所有边都满足题目要求。
如果我们创建第五个组,将第三个组或者第四个组中任何一个节点放到第五个组,至少有一条边连接的两个节点所属的组编号不符合题目要求。
示例 2:
输入:n = 3, edges = [[1,2],[2,3],[3,1]]
输出:-1
解释:如果我们将节点 1 放入第一个组,节点 2 放入第二个组,节点 3 放入第三个组,前两条边满足题目要求,但第三条边不满足题目要求。
没有任何符合题目要求的分组方式。
提示:
1 <= n <= 5001 <= edges.length <= 104edges[i].length == 21 <= ai, bi <= nai != bi- 两个点之间至多只有一条边。
Metadata
- Link: Divide Nodes Into the Maximum Number of Groups
- Difficulty: Hard
- Tag:
You are given a positive integer n representing the number of nodes in an undirected graph. The nodes are labeled from 1 to n.
You are also given a 2D integer array edges, where edges[i] = [ai, bi] indicates that there is a bidirectional edge between nodes ai and bi. Notice that the given graph may be disconnected.
Divide the nodes of the graph into m groups (1-indexed) such that:
- Each node in the graph belongs to exactly one group.
- For every pair of nodes in the graph that are connected by an edge
[ai, bi], ifaibelongs to the group with indexx, andbibelongs to the group with indexy, then|y - x| = 1.
Return the maximum number of groups (i.e., maximum m) into which you can divide the nodes. Return -1 if it is impossible to group the nodes with the given conditions.
Example 1:
Input: n = 6, edges = [[1,2],[1,4],[1,5],[2,6],[2,3],[4,6]]
Output: 4
Explanation: As shown in the image we:
- Add node 5 to the first group.
- Add node 1 to the second group.
- Add nodes 2 and 4 to the third group.
- Add nodes 3 and 6 to the fourth group.
We can see that every edge is satisfied.
It can be shown that that if we create a fifth group and move any node from the third or fourth group to it, at least on of the edges will not be satisfied.
Example 2:
Input: n = 3, edges = [[1,2],[2,3],[3,1]]
Output: -1
Explanation: If we add node 1 to the first group, node 2 to the second group, and node 3 to the third group to satisfy the first two edges, we can see that the third edge will not be satisfied.
It can be shown that no grouping is possible.
Constraints:
1 <= n <= 5001 <= edges.length <= 104edges[i].length == 21 <= ai, bi <= nai != bi- There is at most one edge between any pair of vertices.
Solution
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#define endl "\n"
#define fi first
#define se second
#define all(x) begin(x), end(x)
#define rall rbegin(a), rend(a)
#define bitcnt(x) (__builtin_popcountll(x))
#define complete_unique(a) a.erase(unique(begin(a), end(a)), end(a))
#define mst(x, a) memset(x, a, sizeof(x))
#define MP make_pair
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using VLL = std::vector<ll>;
using VI = std::vector<int>;
using PII = std::pair<int, int>;
using PLL = std::pair<ll, ll>;
using namespace __gnu_pbds;
using namespace std;
template <typename T>
using ordered_set = tree<T, null_type, less<T>, rb_tree_tag, tree_order_statistics_node_update>;
template <typename T, typename S>
inline bool chmax(T &a, const S &b) {
return a < b ? a = b, 1 : 0;
}
template <typename T, typename S>
inline bool chmin(T &a, const S &b) {
return a > b ? a = b, 1 : 0;
}
#ifdef LOCAL
#include <debug.hpp>
#else
#define dbg(...)
#endif
// head
class Solution {
public:
vector<int> color, node;
vector<vector<int>> G;
int n;
bool dfs(int u, int col) {
node.push_back(u);
color[u] = col;
for (const auto &v : G[u]) {
if (color[v] != -1) {
if (color[v] == col) {
return false;
}
continue;
}
if (!dfs(v, col ^ 1)) {
return false;
}
}
return true;
}
int bfs(int st) {
queue<int> q;
q.push(st);
auto dep = vector<int>(n + 5, 0);
dep[st] = 1;
int mx_dep = 1;
while (!q.empty()) {
int u = q.front();
q.pop();
for (const auto &v : G[u]) {
if (dep[v] == 0) {
dep[v] = dep[u] + 1;
mx_dep = max(mx_dep, dep[v]);
q.push(v);
}
}
}
return mx_dep;
}
int magnificentSets(int n, vector<vector<int>> &edges) {
this->n = n;
G = vector<vector<int>>(n + 5, vector<int>());
for (const auto &e : edges) {
int u = e[0];
int v = e[1];
G[u].push_back(v);
G[v].push_back(u);
}
int res = 0;
color = vector<int>(n + 5, -1);
for (int i = 1; i <= n; i++) {
node.clear();
if (color[i] == -1) {
if (!dfs(i, 0)) {
return -1;
}
int cur_res = 0;
for (const auto &a : node) {
cur_res = max(cur_res, bfs(a));
}
res += cur_res;
}
}
return res;
}
};
#ifdef LOCAL
int main() {
return 0;
}
#endif