AC 自动机
概述
AC(Aho–Corasick)自动机是 以 Trie 的结构为基础,结合 KMP 的思想 建立的自动机,用于解决多模式匹配等任务。
AC 自动机本质上是 Trie 上的自动机。
解释
简单来说,建立一个 AC 自动机有两个步骤:
- 基础的 Trie 结构:将所有的模式串构成一棵 Trie;
- KMP 的思想:对 Trie 树上所有的结点构造失配指针。
建立完毕后,就可以利用它进行多模式匹配。
字典树构建
AC 自动机在初始时会将若干个模式串插入到一个 Trie 里,然后在 Trie 上建立 AC 自动机。这个 Trie 就是普通的 Trie,按照 Trie 原本的建树方法建树即可。
需要注意的是,Trie 中的结点表示的是某个模式串的前缀。我们在后文也将其称作状态。一个结点表示一个状态,Trie 的边就是状态的转移。
形式化地说,对于若干个模式串
失配指针
AC 自动机利用一个 fail 指针来辅助多模式串的匹配。
状态
fail 指针与 KMP 中的 next 指针相比:
- 共同点:两者同样是在失配的时候用于跳转的指针。
- 不同点:next 指针求的是最长 Border(即最长的相同前后缀),而 fail 指针指向所有模式串的前缀中匹配当前状态的最长后缀。
因为 KMP 只对一个模式串做匹配,而 AC 自动机要对多个模式串做匹配。有可能 fail 指针指向的结点对应着另一个模式串,两者前缀不同。
总结下来,AC 自动机的失配指针指向当前状态的最长后缀状态。
注意:AC 自动机在做匹配时,同一位上可匹配多个模式串。
构建指针
下面介绍构建 fail 指针的 基础思想:
构建 fail 指针,可以参考 KMP 中构造 next 指针的思想。
考虑字典树中当前的结点
- 如果
存在:则让 的 fail 指针指向 。相当于在 和 后面加一个字符 ,分别对应 和 ; - 如果
不存在:那么我们继续找到 。重复判断过程,一直跳 fail 指针直到根结点; - 如果依然不存在,就让 fail 指针指向根结点。
如此即完成了
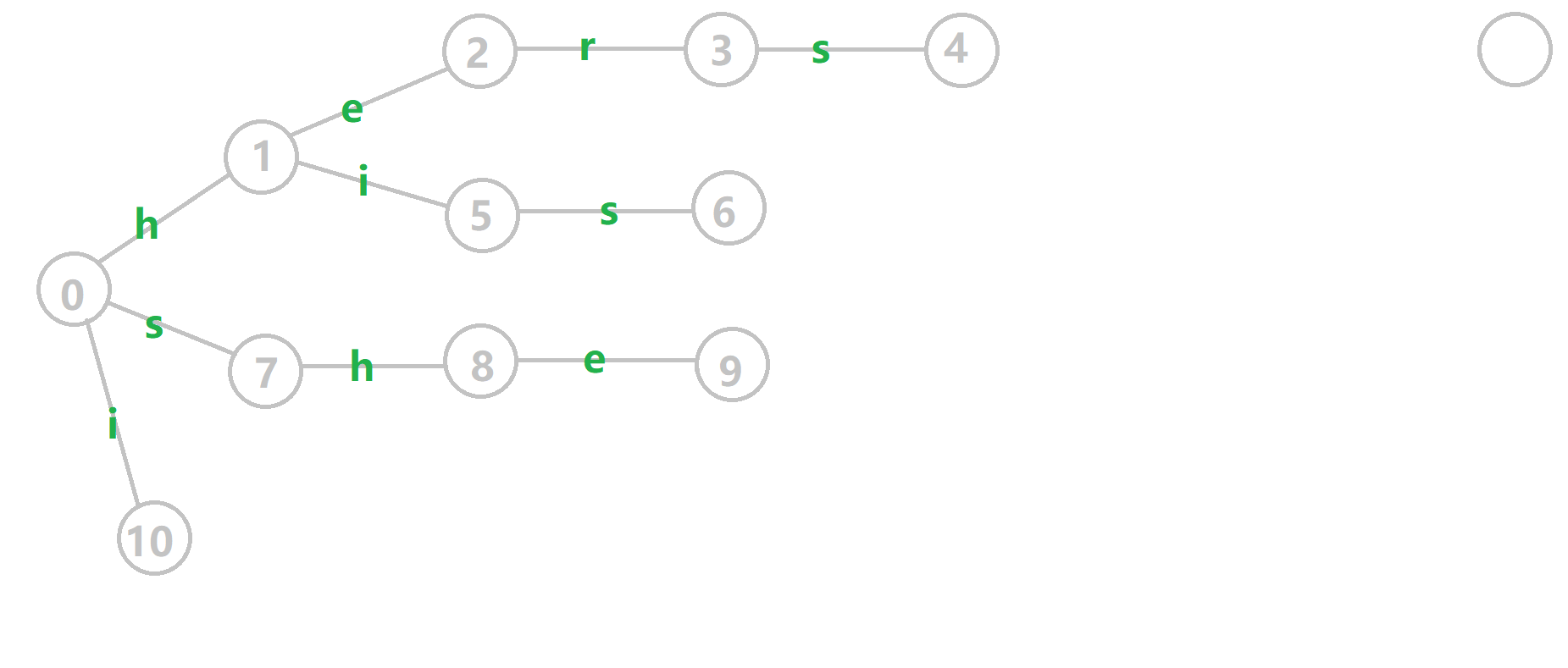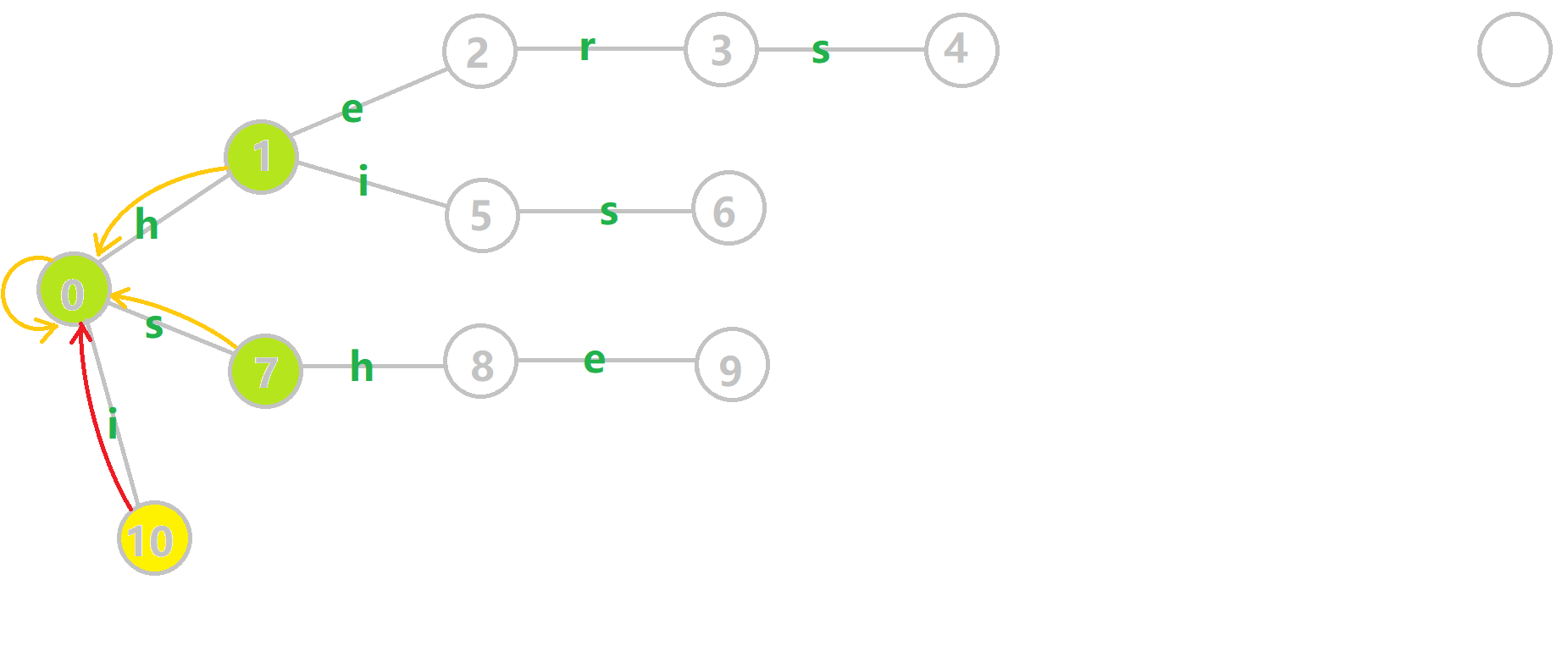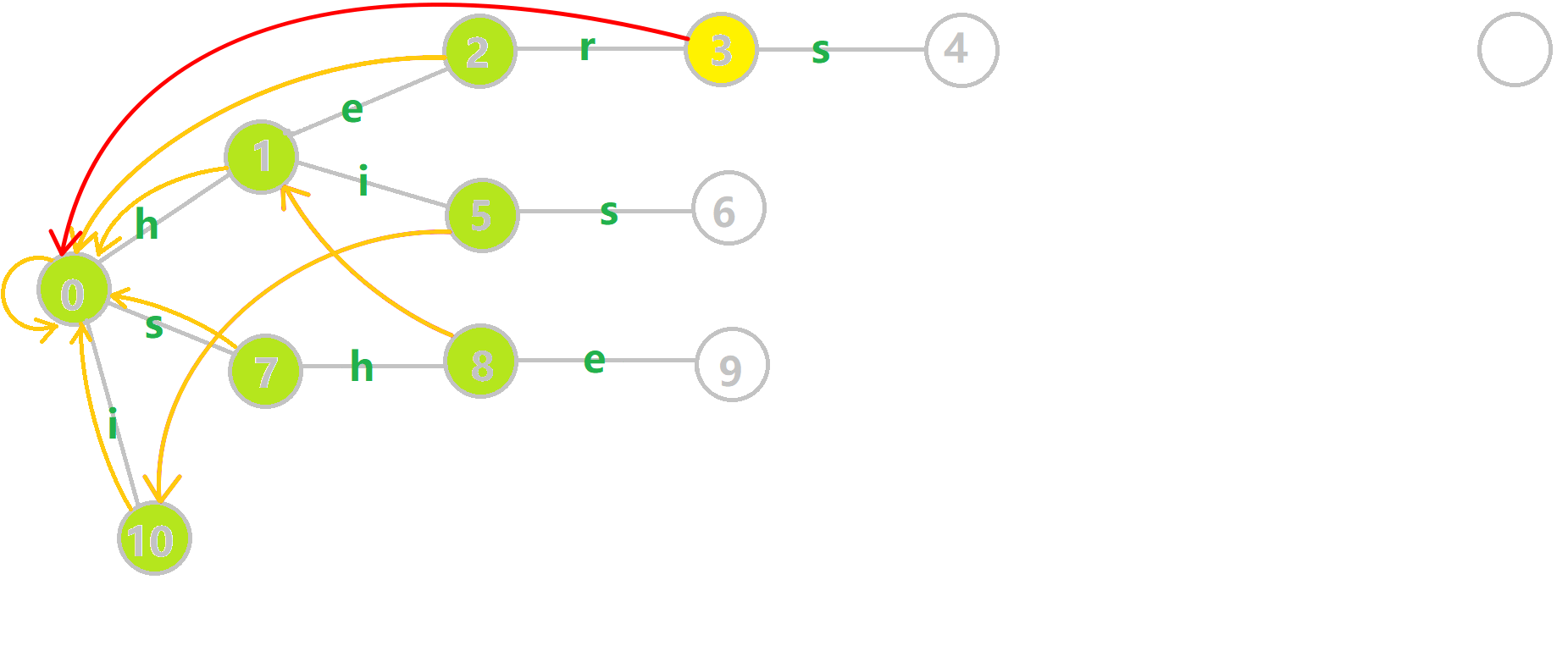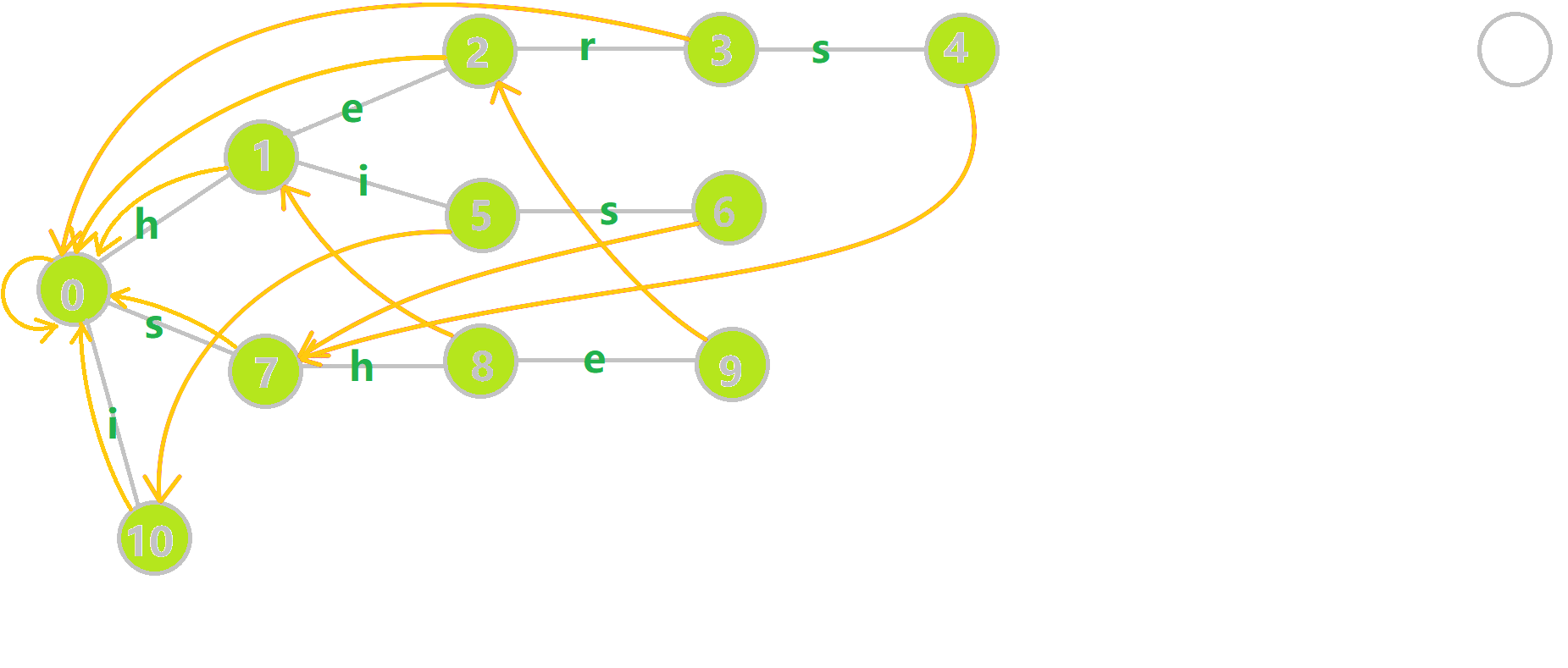
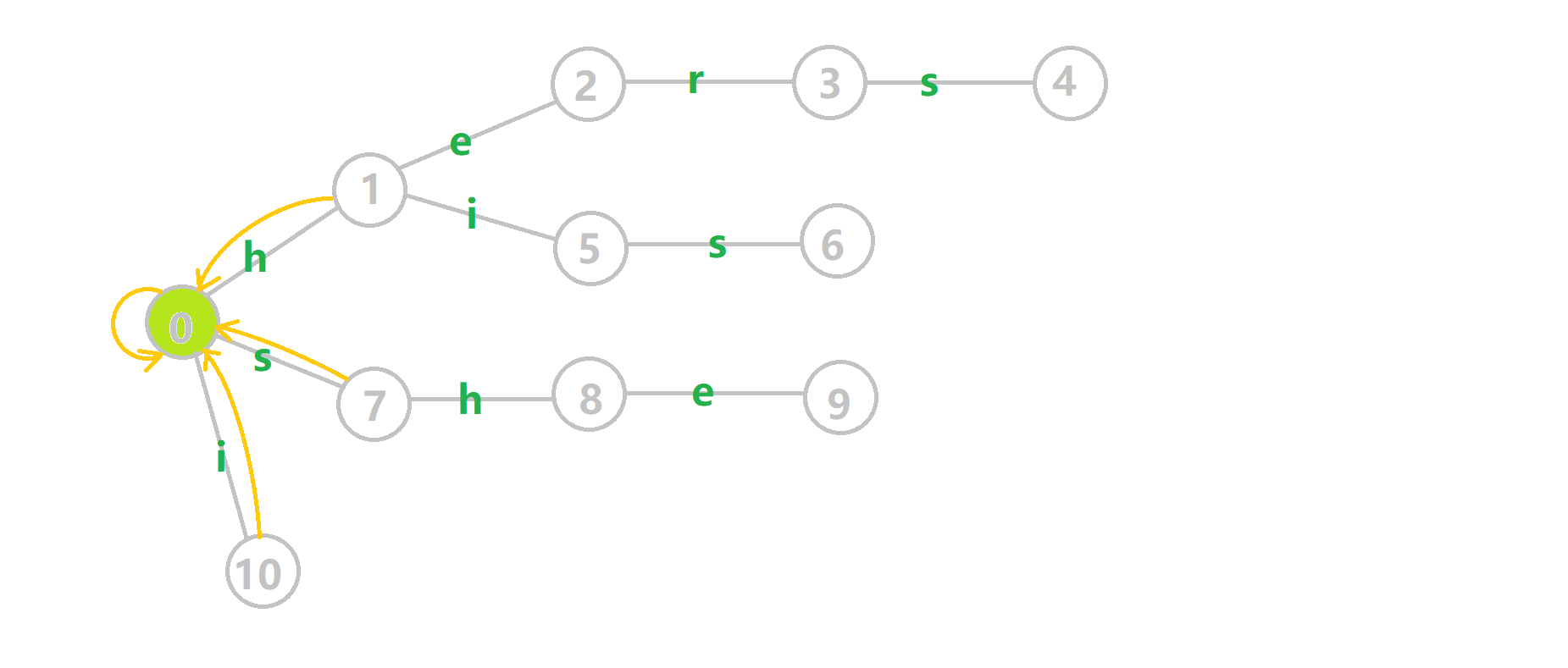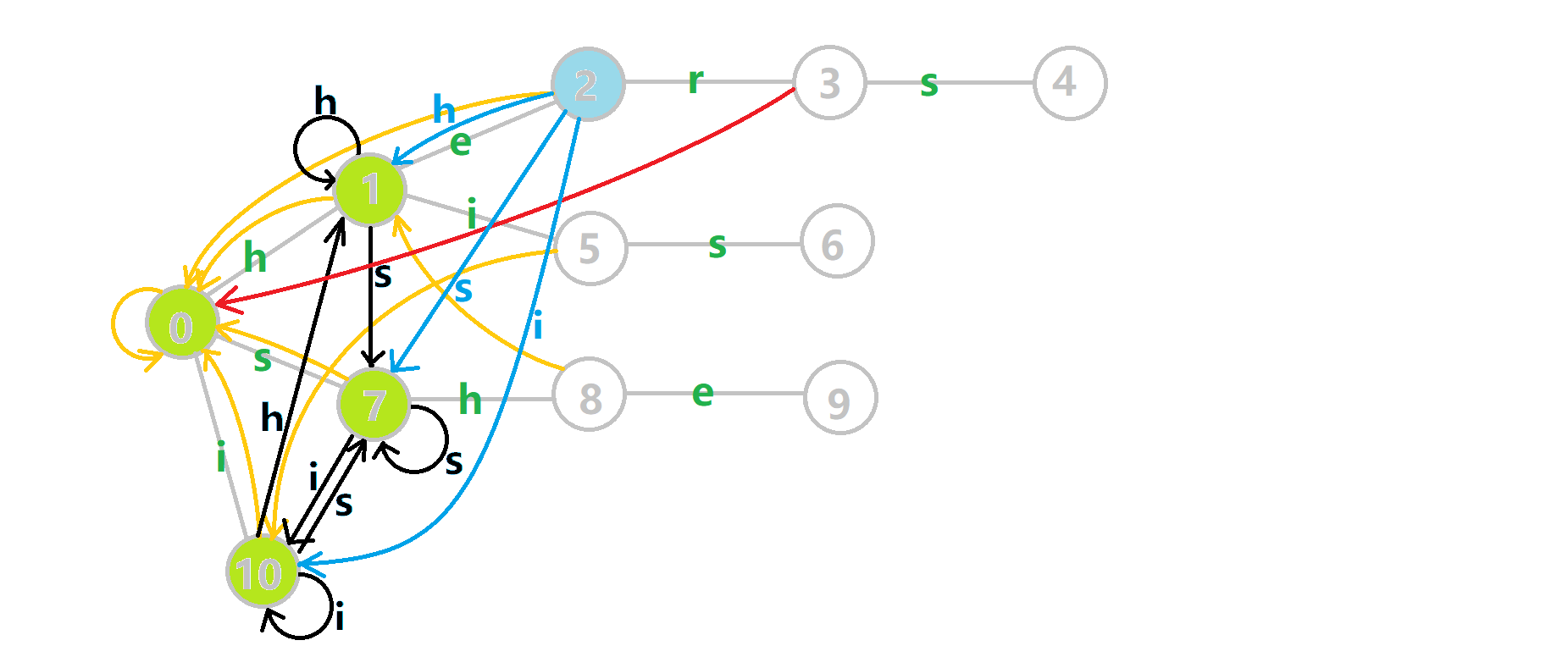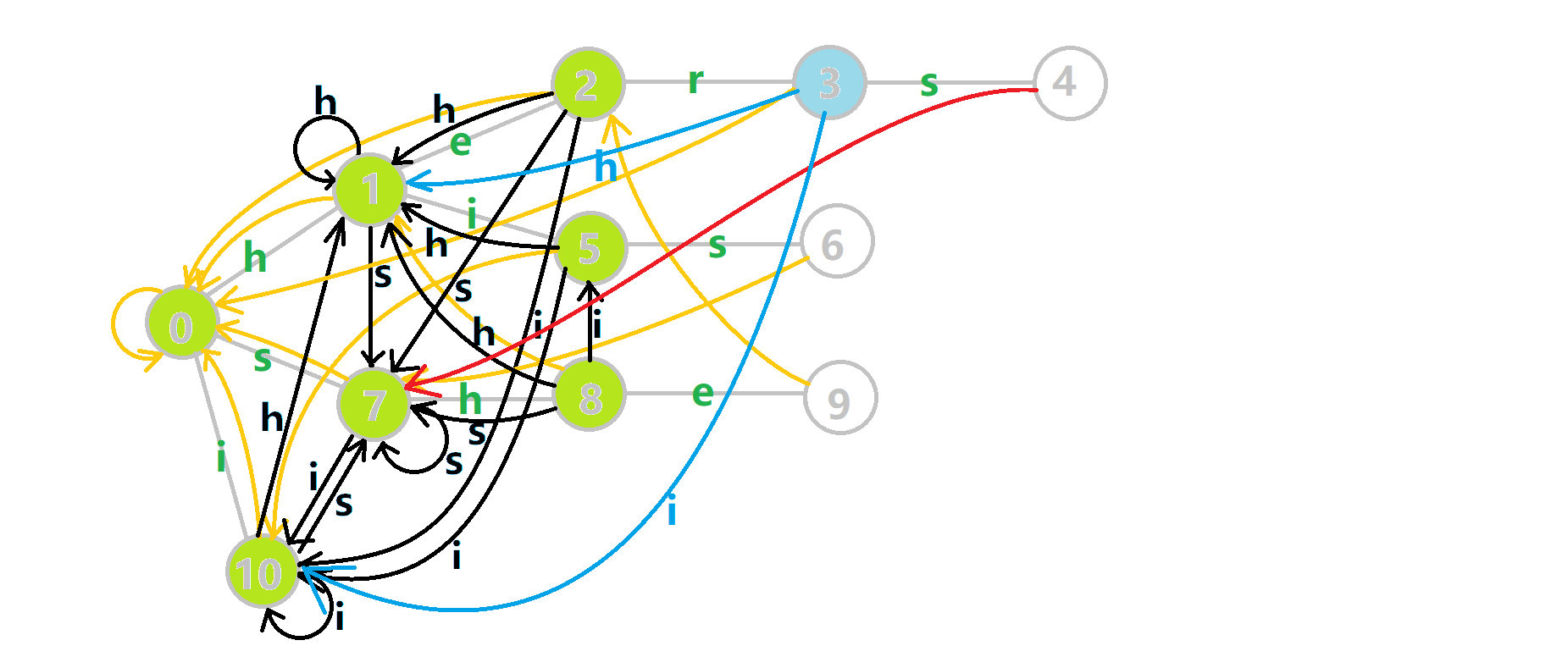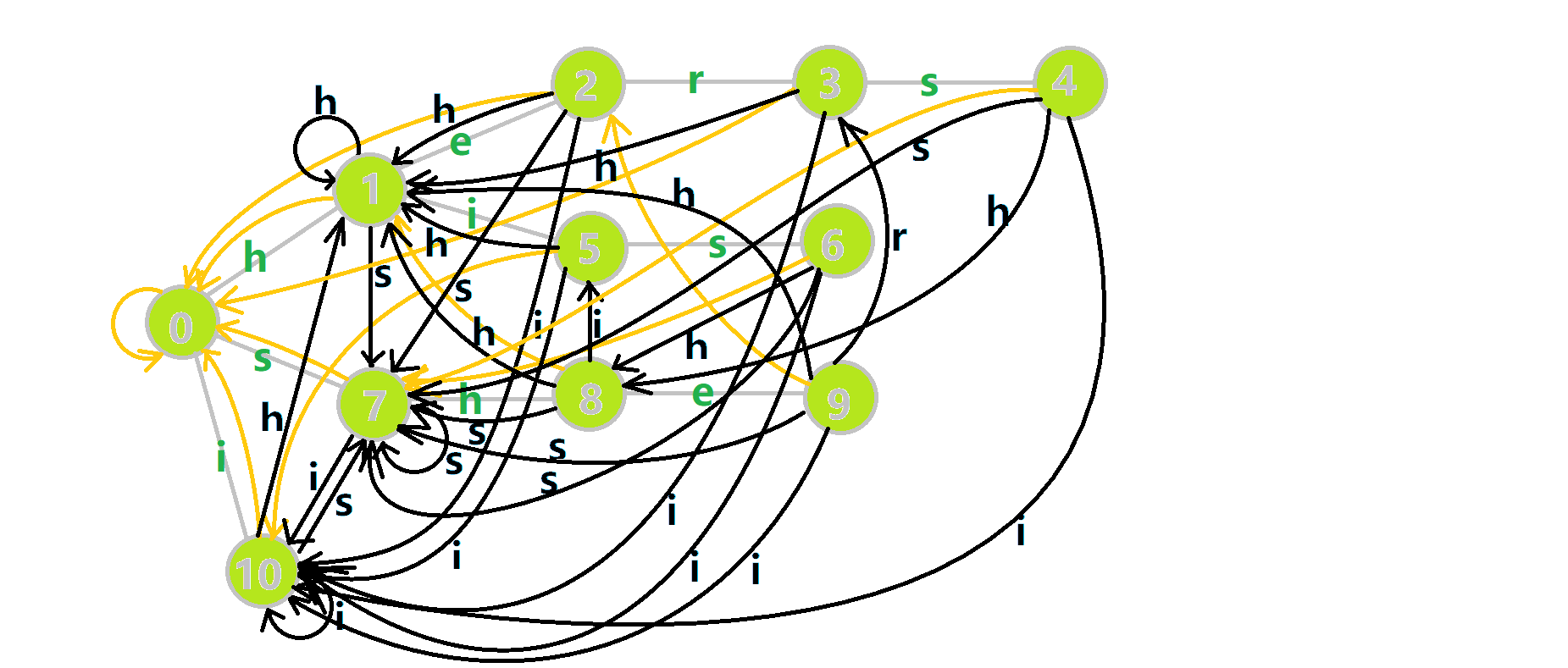
例子
下面将使用若干张 GIF 动图来演示对字符串
- 黄色结点:当前的结点
。 - 绿色结点:表示已经 BFS 遍历完毕的结点。
- 橙色的边:fail 指针。
- 红色的边:当前求出的 fail 指针。
我们重点分析结点
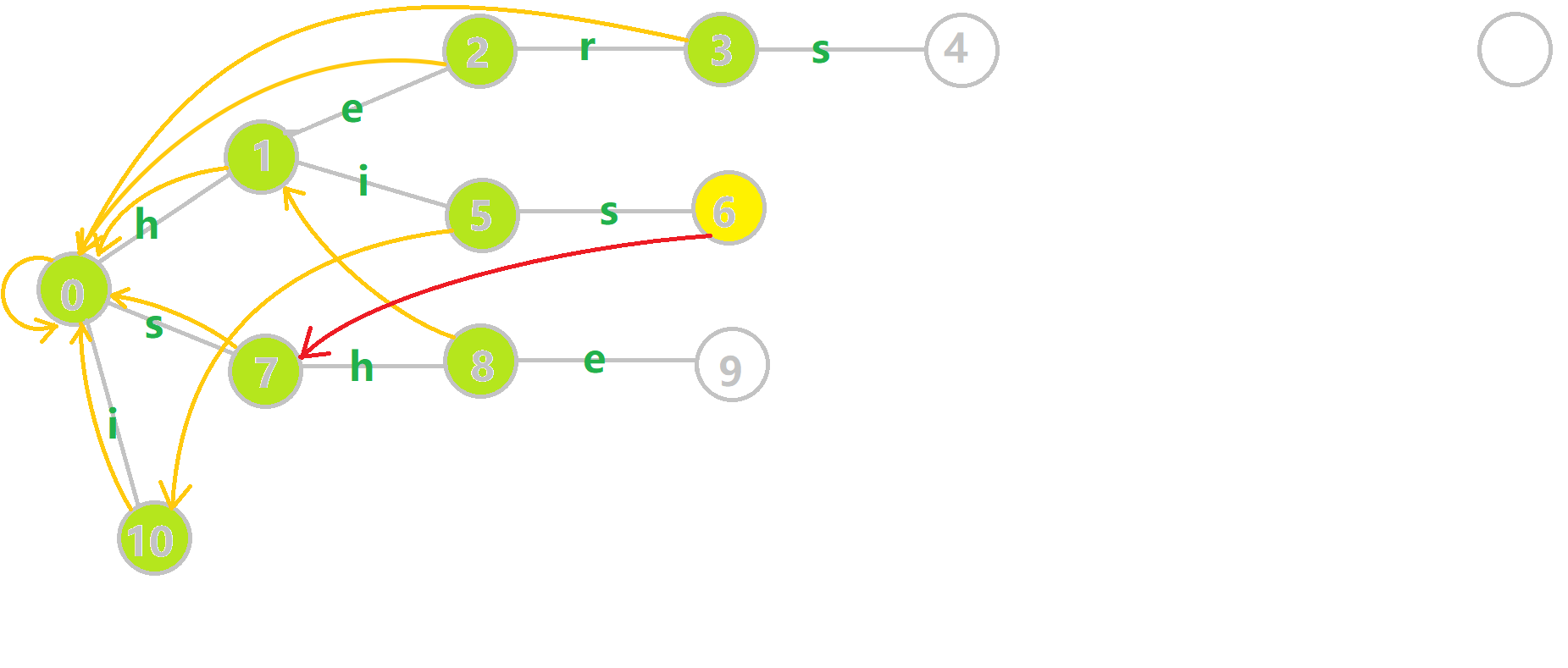
找到
下图展示了构建完毕的状态:
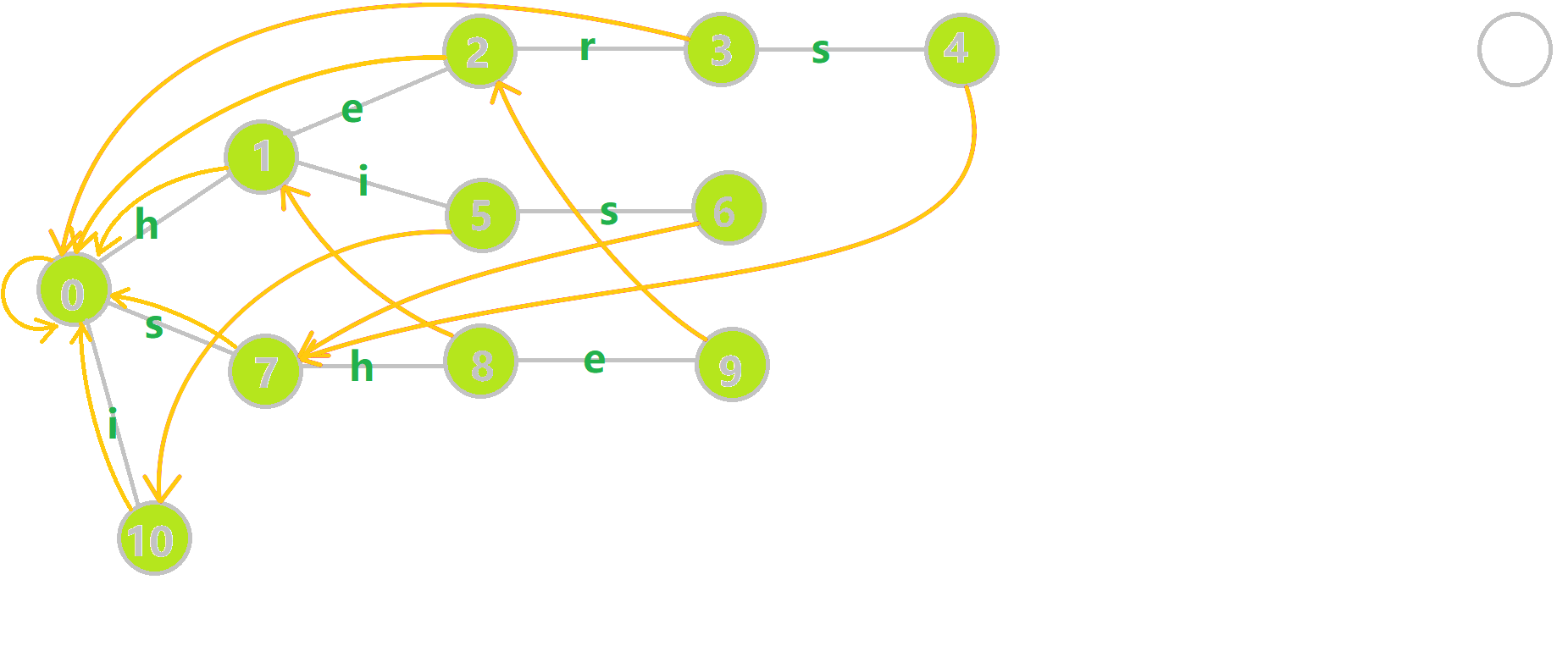
字典树与字典图
关注构建函数 build,该函数的目标有两个,一个是构建 fail 指针,一个是构建自动机。相关变量定义如下:
tr[u].son[c]:有两种理解方式。我们可以简单理解为字典树上的一条边,即;也可以理解为从状态(结点) 后加一个字符 到达的状态(结点),即一个状态转移函数 。为了方便,下文中我们将用第二种理解方式。 - 队列
q:用于 BFS 遍历字典树。 tr[u].fail:结点的 fail 指针。
实现
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) q.push(tr[0].son[i]);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) {
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i];
q.push(tr[u].son[i]);
} else
tr[u].son[i] = tr[tr[u].fail].son[i];
}
}
}
解释
build 函数将结点按 BFS 顺序入队,依次求 fail 指针。这里的字典树根结点为
然后开始 BFS:每次取出队首的结点
- 如果
存在,我们就将 的 fail 指针赋值为 。根据之前的描述,我们应该用 while循环,不停地跳 fail 指针,判断是否存在字符对应的结点,然后赋值,但此处通过特殊处理简化了这些代码,将在下文说明; - 否则,令
指向 的状态。
这里的处理是,通过 else 语句的代码修改字典树的结构,将不存在的字典树的状态链接到了失配指针的对应状态。在原字典树中,每一个结点代表一个字符串
而
换言之在 Trie 上跳转的时侯,我们只会从
Trie 的结点的孩子数组 son 还有另一种比较简单的理解方式:如果在位置 son 直接记录记录下一个能匹配的位置,这样保证了程序的时间复杂度。
此处对字典树结构的修改,可以使得匹配转移更加完善。同时它将 fail 指针跳转的路径做了压缩,使得本来需要跳很多次 fail 指针变成跳一次。
过程
这里依然用若干张 GIF 动图展示构建过程:
- 蓝色结点:BFS 遍历到的结点
。 - 蓝色的边:当前结点下,AC 自动机修改字典树结构连出的边。
- 黑色的边:AC 自动机修改字典树结构连出的边。
- 红色的边:当前结点求出的 fail 指针。
- 黄色的边:fail 指针。
- 灰色的边:字典树的边。
可以发现,众多交错的黑色边将字典树变成了 字典图。图中省略了连向根结点的黑边(否则会更乱)。我们重点分析一下结点
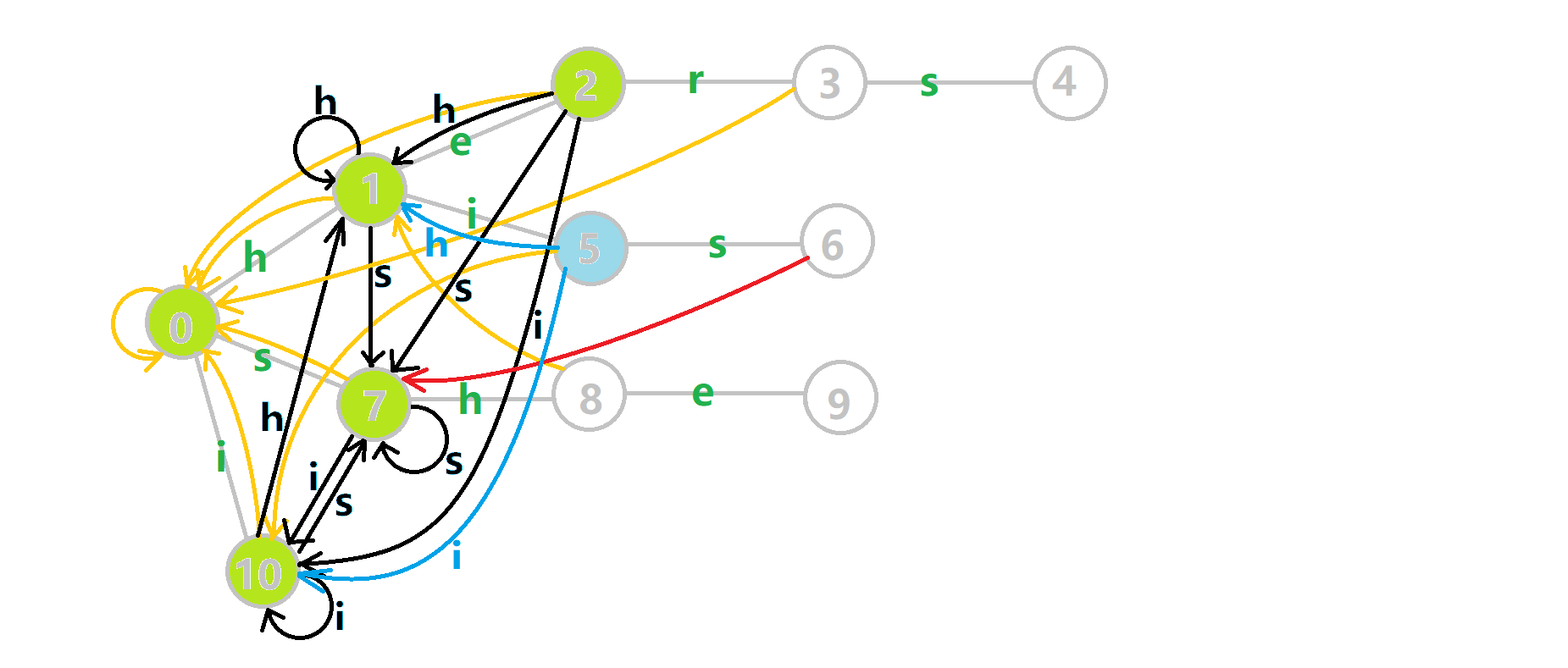
本来的策略是找 fail 指针,于是我们跳到
这就是 build 完成的两件事:构建 fail 指针和建立字典图。这个字典图也会在查询的时候起到关键作用。
多模式匹配
接下来分析匹配函数 query:
实现
解释
这里 res 即返回的答案。循环遍历匹配串,
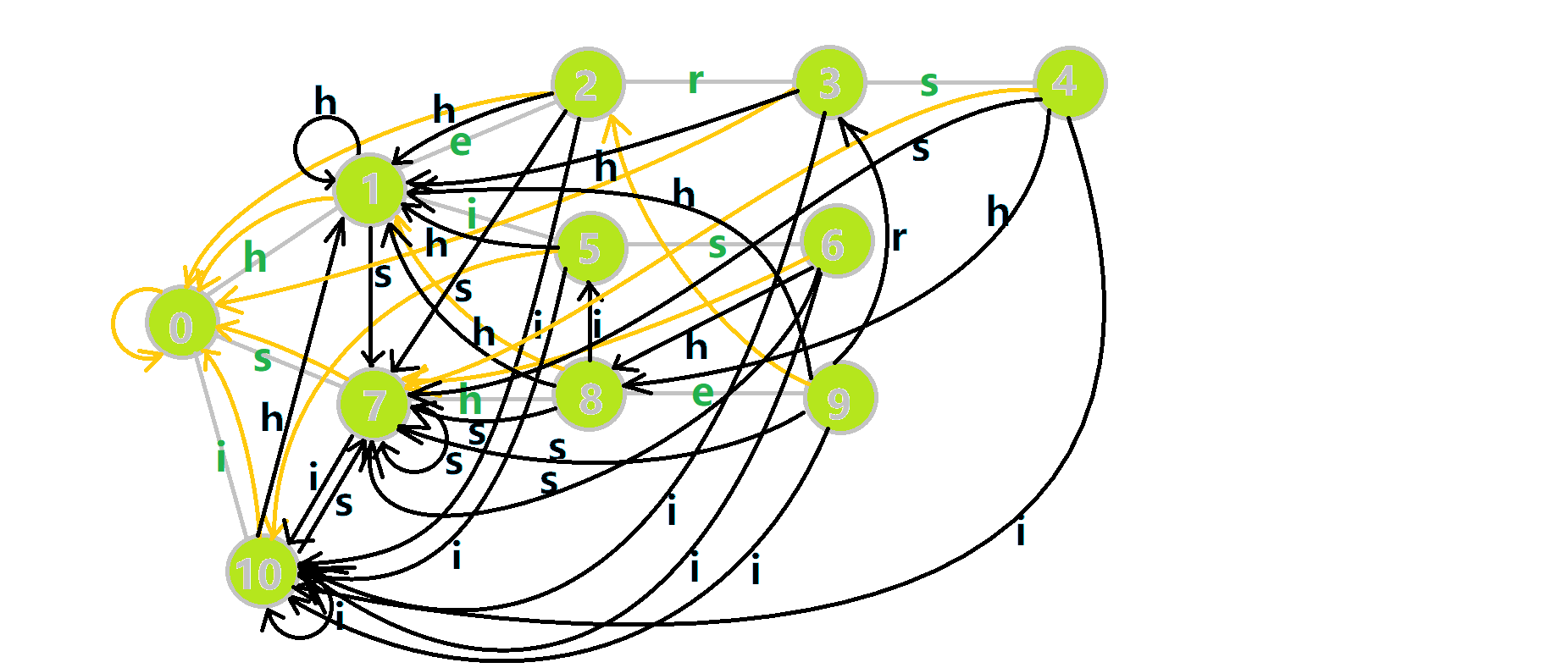
我们从根结点开始尝试匹配
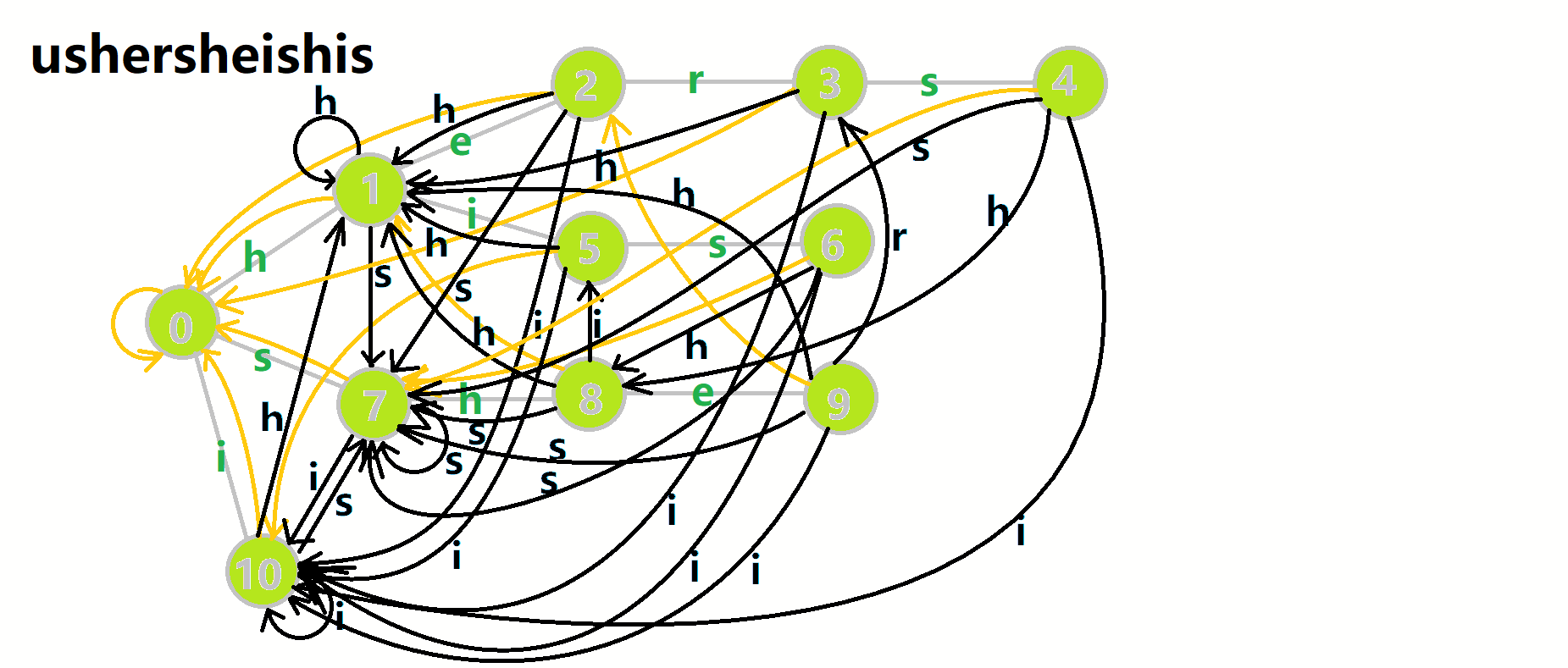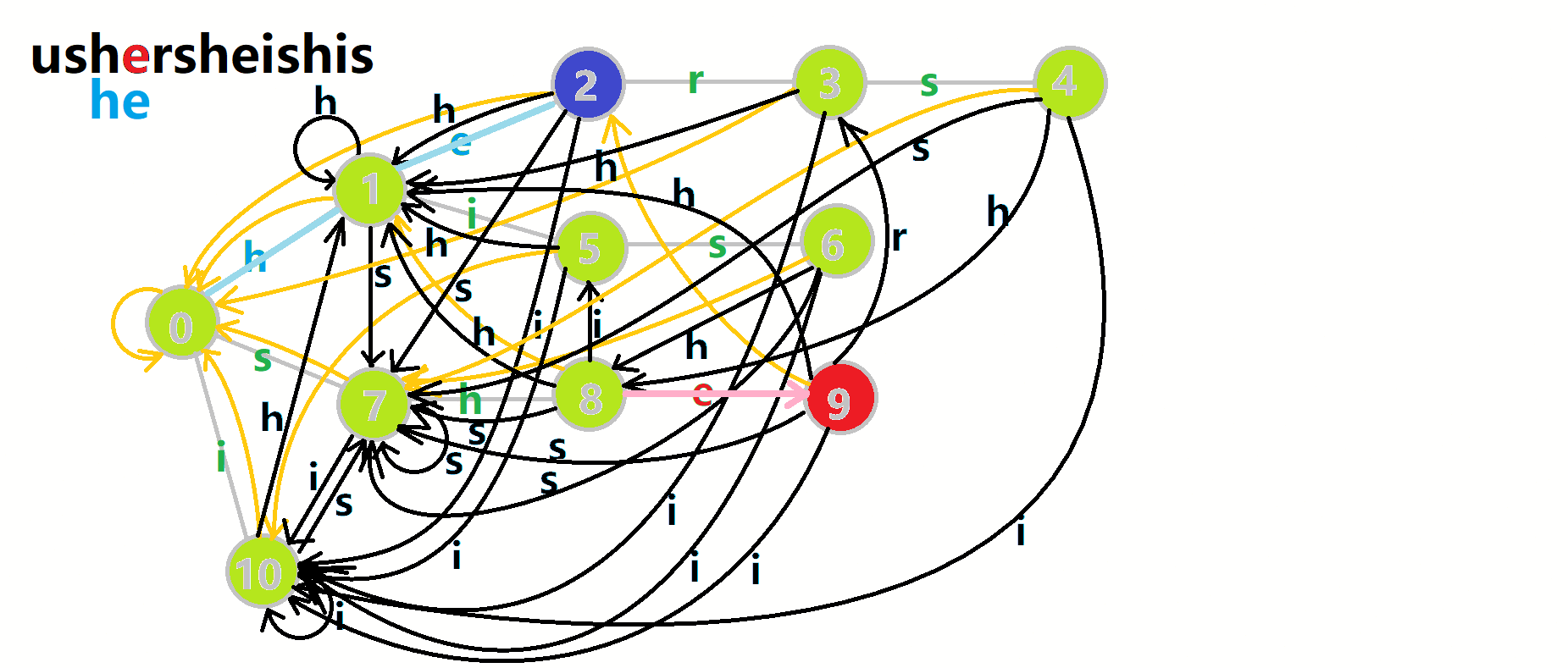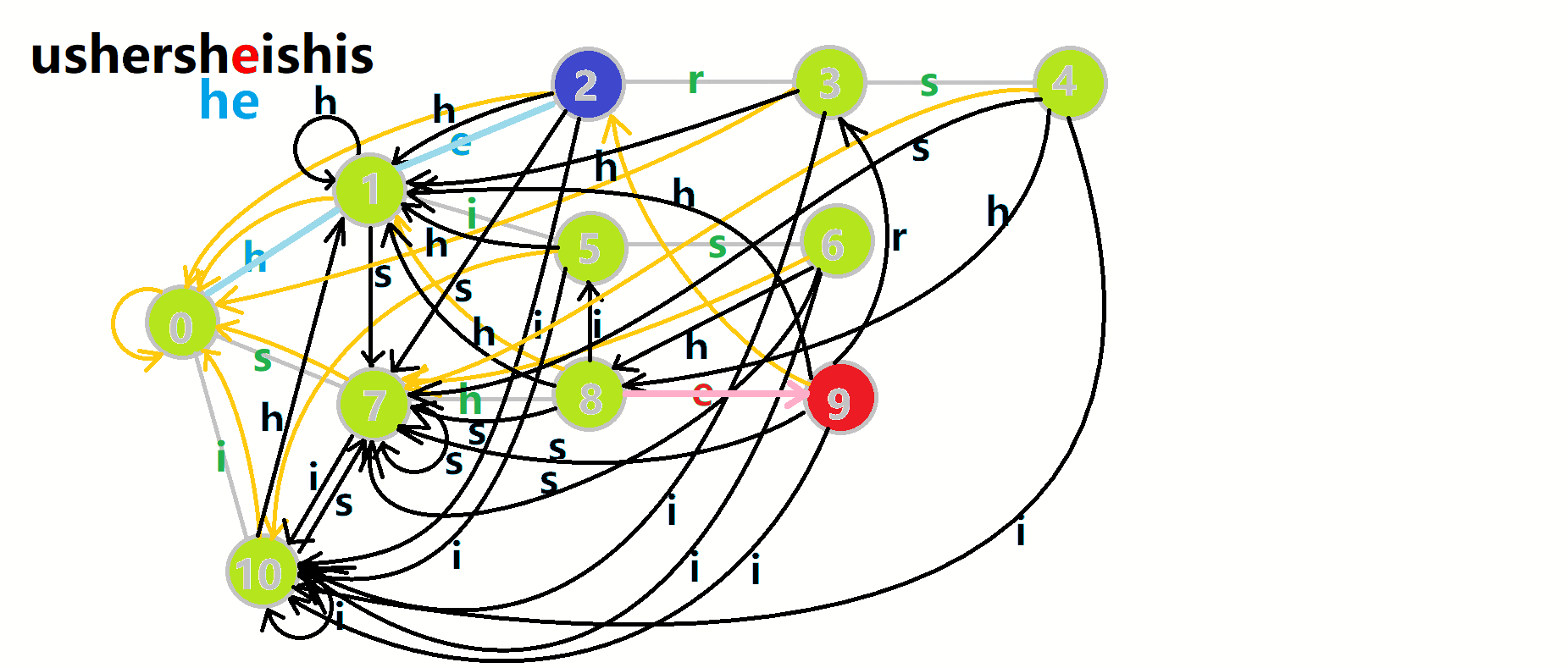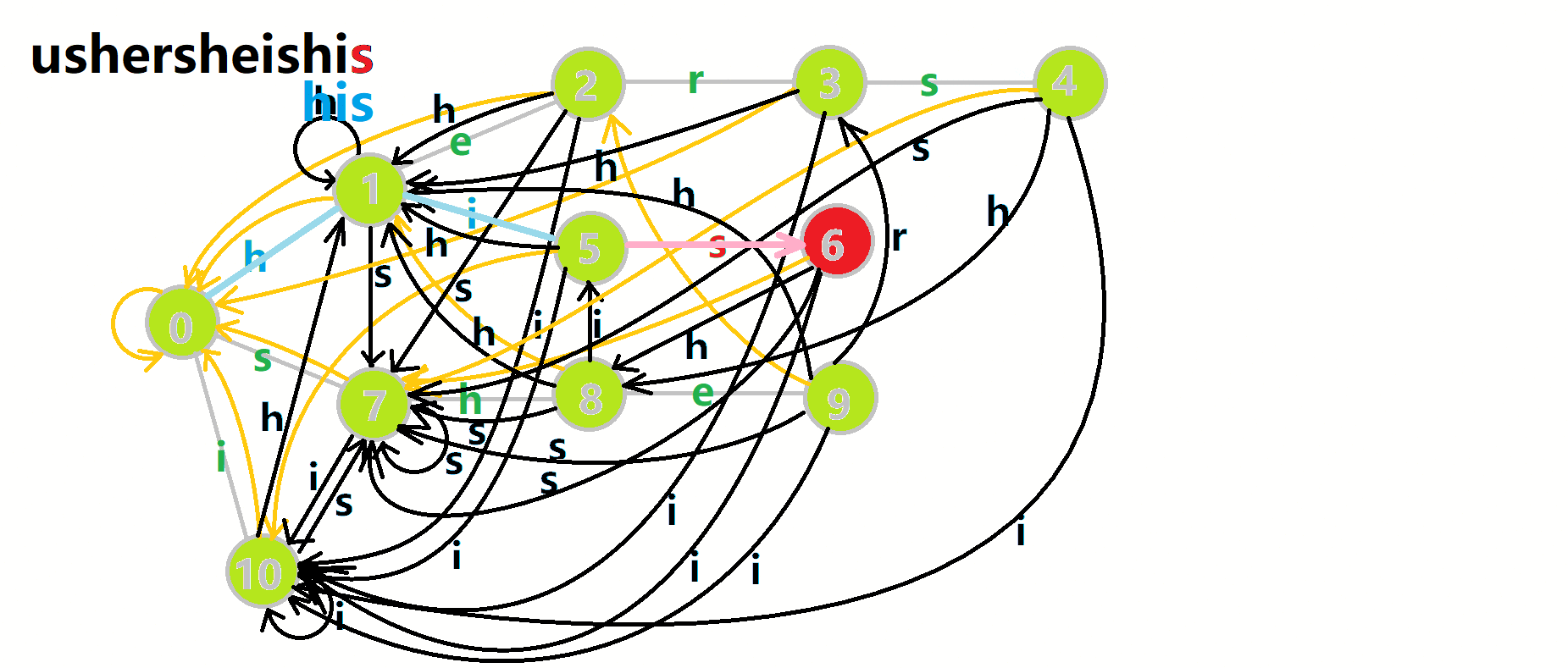
- 红色结点:
结点。 - 粉色箭头:
在自动机上的跳转。 - 蓝色的边:成功匹配的模式串。
- 蓝色结点:示跳 fail 指针时的结点(状态)。
效率优化
题目请参考洛谷 P5357【模板】AC 自动机。
因为我们的 AC 自动机中,每次匹配,会一直向 fail 边跳来找到所有的匹配,但是这样的效率较低,在某些题目中会超时。
那么需要如何优化呢?首先需要了解到 fail 指针的一个性质:一个 AC 自动机中,如果只保留 fail 边,那么剩余的图一定是一棵树。
这是显然的,因为 fail 不会成环,且深度一定比现在低,所以得证。
这样 AC 自动机的匹配就可以转化为在 fail 树上的链求和问题,只需要优化一下该部分就可以了。
这里提供两种思路。
拓扑排序优化
观察到时间主要浪费在在每次都要跳 fail。如果我们可以预先记录,最后一并求和,那么效率就会优化。
于是我们按照 fail 树,做一次内向树上的拓扑排序,就能一次性求出所有模式串的出现次数。
build 函数在原先的基础上,增加了入度统计一部分,为拓扑排序做准备。
构建
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) q.push(tr[0].son[i]);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) {
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i];
tr[tr[tr[u].fail].son[i]].du++; // 入度计数
q.push(tr[u].son[i]);
} else
tr[u].son[i] = tr[tr[u].fail].son[i];
}
}
}
然后我们在查询的时候就可以只为找到结点的 ans 打上标记,在最后再用拓扑排序求出答案。
查询
void query(const char t[]) {
int u = 0;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a'];
tr[u].ans++;
}
}
void topu() {
queue<int> q;
for (int i = 0; i <= tot; i++)
if (tr[i].du == 0) q.push(i);
while (!q.empty()) {
int u = q.front();
q.pop();
ans[tr[u].idx] = tr[u].ans;
int v = tr[u].fail;
tr[v].ans += tr[u].ans;
if (!--tr[v].du) q.push(v);
}
}
最后是主函数:
主函数
完整代码
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
constexpr int N = 2e5 + 6;
constexpr int LEN = 2e6 + 6;
constexpr int SIZE = 2e5 + 6;
int n;
namespace AC {
struct Node {
int son[26]; // 子结点
int ans; // 匹配计数
int fail; // fail 指针
int du; // 入度
int idx;
void init() { // 结点初始化
memset(son, 0, sizeof(son));
ans = fail = idx = 0;
}
} tr[SIZE];
int tot; // 结点总数
int ans[N], pidx;
void init() {
tot = pidx = 0;
tr[0].init();
}
void insert(char s[], int &idx) {
int u = 0;
for (int i = 1; s[i]; i++) {
int &son = tr[u].son[s[i] - 'a']; // 下一个子结点的引用
if (!son) son = ++tot, tr[son].init(); // 如果没有则插入新结点,并初始化
u = son; // 从下一个结点继续
}
// 由于有可能出现相同的模式串,需要将相同的映射到同一个编号
if (!tr[u].idx) tr[u].idx = ++pidx; // 第一次出现,新增编号
idx = tr[u].idx; // 这个模式串的编号对应这个结点的编号
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) q.push(tr[0].son[i]);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) { // 存在对应子结点
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i]; // 只用跳一次 fail 指针
tr[tr[tr[u].fail].son[i]].du++; // 入度计数
q.push(tr[u].son[i]); // 并加入队列
} else
tr[u].son[i] =
tr[tr[u].fail]
.son[i]; // 将不存在的字典树的状态链接到了失配指针的对应状态
}
}
}
void query(char t[]) {
int u = 0;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a']; // 转移
tr[u].ans++;
}
}
void topu() {
queue<int> q;
for (int i = 0; i <= tot; i++)
if (tr[i].du == 0) q.push(i);
while (!q.empty()) {
int u = q.front();
q.pop();
ans[tr[u].idx] = tr[u].ans;
int v = tr[u].fail;
tr[v].ans += tr[u].ans;
if (!--tr[v].du) q.push(v);
}
}
} // namespace AC
char s[LEN];
int idx[N];
int main() {
AC::init();
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
AC::insert(s, idx[i]);
AC::ans[i] = 0;
}
AC::build();
scanf("%s", s + 1);
AC::query(s);
AC::topu();
for (int i = 1; i <= n; i++) {
printf("%d\n", AC::ans[idx[i]]);
}
return 0;
}
DFS 优化
和拓扑排序的思路接近,不过我们使用 DFS 来代替拓扑排序。其实这两种方法本质上是相同的,都是将 fail 树的子树求和。
完整代码请见总结模板 3。
AC 自动机上 DP
这部分将以 P2292 [HNOI2004] L 语言 为例题讲解。
不难想到一个朴素的思路:建立 AC 自动机,在 AC 自动机上对于所有 fail 指针的子串转移,最后取最大值得到答案。
主要代码如下。若不熟悉代码中的类型定义,可以先看末尾的完整代码:
查询部分主要代码
int query(const char t[]) {
int u = 0, len = strlen(t + 1);
for (int i = 1; i <= len; i++) dp[i] = 0;
for (int i = 1; i <= len; i++) {
u = tr[u].son[t[i] - 'a'];
for (int j = u; j; j = tr[j].fail) {
if (tr[j].idx && (dp[i - tr[j].depth] || i - tr[j].depth == 0)) {
dp[i] = dp[i - tr[j].depth] + tr[j].depth;
}
}
}
int ans = 0;
for (int i = 1; i <= len; i++) ans = std::max(ans, dp[i]);
return ans;
}
但是这样的思路复杂度不是线性(因为要跳每个结点的 fail),会在第二个子任务中超时,所以我们需要进行优化。
我们再看看题目的特殊性质,我们发现所有单词的长度只有
我们发现,目前的时间瓶颈主要在跳 fail 这一步,如果我们可以将这一步优化到
我们可以将前
那么我们在 build 的时候就可以这么写:
构建 fail 指针
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) {
q.push(tr[0].son[i]);
tr[tr[0].son[i]].depth = 1;
}
while (!q.empty()) {
int u = q.front();
q.pop();
int v = tr[u].fail;
// 对状态的更新在这里
tr[u].stat = tr[v].stat;
if (tr[u].idx) tr[u].stat |= 1 << tr[u].depth;
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) {
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i];
tr[tr[u].son[i]].depth = tr[u].depth + 1; // 记录深度
q.push(tr[u].son[i]);
} else
tr[u].son[i] = tr[tr[u].fail].son[i];
}
}
}
然后查询时就可以去掉跳 fail 的循环,将代码简化如下:
查询
我们的 tr[u].stat 维护的是从结点 st 则维护的是查询字符串走到现在,前
& 运算后结果不为
完整代码
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
constexpr int N = 20 + 6, M = 50 + 6;
constexpr int LEN = 2e6 + 6;
constexpr int SIZE = 450 + 6;
int n, m;
namespace AC {
struct Node {
int son[26];
int fail;
int idx;
int depth;
unsigned stat;
void init() {
memset(son, 0, sizeof(son));
fail = idx = depth = 0;
}
} tr[SIZE];
int tot;
void init() {
tot = 0;
tr[0].init();
}
void insert(char s[], int idx) {
int u = 0;
for (int i = 1; s[i]; i++) {
int &son = tr[u].son[s[i] - 'a'];
if (!son) son = ++tot, tr[son].init();
u = son;
}
tr[u].idx = idx;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) {
q.push(tr[0].son[i]);
tr[tr[0].son[i]].depth = 1;
}
while (!q.empty()) {
int u = q.front();
q.pop();
int v = tr[u].fail;
// 对状态的更新在这里
tr[u].stat = tr[v].stat;
if (tr[u].idx) tr[u].stat |= 1 << tr[u].depth;
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) {
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i];
tr[tr[u].son[i]].depth = tr[u].depth + 1; // 记录深度
q.push(tr[u].son[i]);
} else
tr[u].son[i] = tr[tr[u].fail].son[i];
}
}
}
int query(char t[]) {
int u = 0, mx = 0;
unsigned st = 1;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a'];
st <<= 1;
if (tr[u].stat & st) st |= 1, mx = i;
}
return mx;
}
} // namespace AC
char s[LEN];
int main() {
AC::init();
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
AC::insert(s, i);
}
AC::build();
for (int i = 1; i <= m; i++) {
scanf("%s", s + 1);
printf("%d\n", AC::query(s));
}
return 0;
}
总结
时间复杂度:定义
模板 1
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
constexpr int N = 1e6 + 6;
constexpr int LEN = 1e6 + 6;
constexpr int SIZE = 1e6 + 6;
int n;
namespace AC {
struct Node {
int son[26]; // 子结点
int cnt; // 尾为该结点的串的个数
int fail; // fail 指针
void init() { // 结点初始化
memset(son, 0, sizeof(son));
cnt = fail = 0;
}
} tr[SIZE];
int tot; // 结点总数
void init() {
tot = 0;
tr[0].init();
}
void insert(char s[]) {
int u = 0;
for (int i = 1; s[i]; i++) {
int &son = tr[u].son[s[i] - 'a']; // 下一个子结点的引用
if (!son) son = ++tot, tr[son].init(); // 如果没有则插入新结点,并初始化
u = son; // 从下一个结点继续
}
tr[u].cnt++;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) q.push(tr[0].son[i]);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) { // 存在对应子结点
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i]; // 只用跳一次 fail 指针
q.push(tr[u].son[i]); // 并加入队列
} else
tr[u].son[i] =
tr[tr[u].fail]
.son[i]; // 将不存在的字典树的状态链接到了失配指针的对应状态
}
}
}
int query(char t[]) {
int u = 0, res = 0;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a']; // 转移
for (int j = u; j && tr[j].cnt != -1; j = tr[j].fail) {
res += tr[j].cnt, tr[j].cnt = -1;
}
}
return res;
}
} // namespace AC
char s[LEN];
int main() {
AC::init();
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
AC::insert(s);
}
AC::build();
scanf("%s", s + 1);
printf("%d", AC::query(s));
return 0;
}
模板 2
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
constexpr int N = 150 + 6;
constexpr int LEN = 1e6 + 6;
constexpr int SIZE = N * 70 + 6;
int n;
namespace AC {
struct Node {
int son[26];
int fail;
int idx;
void init() {
memset(son, 0, sizeof(son));
idx = fail = 0;
}
} tr[SIZE];
int tot;
void init() {
tot = 0;
tr[0].init();
}
void insert(char s[], int idx) { // 将第 idx 个字符串 s 插入
int u = 0;
for (int i = 1; s[i]; i++) {
int &son = tr[u].son[s[i] - 'a'];
if (!son) son = ++tot, tr[son].init();
u = son;
}
tr[u].idx = idx;
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) q.push(tr[0].son[i]);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) {
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i];
q.push(tr[u].son[i]);
} else
tr[u].son[i] = tr[tr[u].fail].son[i];
}
}
}
int query(char t[], int cnt[]) {
int u = 0, res = 0;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a'];
for (int j = u; j; j = tr[j].fail)
++cnt[tr[j].idx]; // 统计每个字符串出现的次数
}
for (int i = 0; i <= tot; ++i)
if (tr[i].idx) res = max(res, cnt[tr[i].idx]);
return res;
}
} // namespace AC
char s[N][75], t[LEN];
int cnt[N]; // 每一个字符串出现的次数
int main() {
while (scanf("%d", &n) != EOF && n != 0) {
AC::init();
for (int i = 1; i <= n; i++) {
scanf("%s", s[i] + 1);
AC::insert(s[i], i);
cnt[i] = 0;
}
AC::build();
scanf("%s", t + 1);
int x = AC::query(t, cnt);
printf("%d\n", x);
for (int i = 1; i <= n; i++)
if (cnt[i] == x) printf("%s\n", s[i] + 1);
}
return 0;
}
模版 3
#include <cstdio>
#include <cstring>
#include <queue>
#include <vector>
using namespace std;
constexpr int N = 2e5 + 6;
constexpr int LEN = 2e6 + 6;
constexpr int SIZE = 2e5 + 6;
int n;
namespace AC {
struct Node {
int son[26];
int ans;
int fail;
int idx;
void init() {
memset(son, 0, sizeof(son));
ans = idx = 0;
}
} tr[SIZE];
int tot;
int ans[N], pidx;
vector<int> g[SIZE]; // fail 树
void init() {
tot = pidx = 0;
tr[0].init();
}
void insert(char s[], int &idx) {
int u = 0;
for (int i = 1; s[i]; i++) {
int &son = tr[u].son[s[i] - 'a'];
if (!son) son = ++tot, tr[son].init();
u = son;
}
// 由于有可能出现相同的模式串,需要将相同的映射到同一个编号
if (!tr[u].idx) tr[u].idx = ++pidx; // 第一次出现,新增编号
idx = tr[u].idx; // 这个模式串的编号对应这个结点的编号
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) {
q.push(tr[0].son[i]);
g[0].push_back(tr[0].son[i]); // 不要忘记这里的 fail
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) {
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i];
g[tr[tr[u].fail].son[i]].push_back(tr[u].son[i]); // 记录 fail 树
q.push(tr[u].son[i]);
} else
tr[u].son[i] = tr[tr[u].fail].son[i];
}
}
}
void query(char t[]) {
int u = 0;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a'];
tr[u].ans++;
}
}
void dfs(int u) {
for (int v : g[u]) {
dfs(v);
tr[u].ans += tr[v].ans;
}
ans[tr[u].idx] = tr[u].ans;
}
} // namespace AC
char s[LEN];
int idx[N];
int main() {
AC::init();
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
AC::insert(s, idx[i]);
AC::ans[i] = 0;
}
AC::build();
scanf("%s", s + 1);
AC::query(s);
AC::dfs(0);
for (int i = 1; i <= n; i++) {
printf("%d\n", AC::ans[idx[i]]);
}
return 0;
}
拓展
确定有限状态自动机
作为拓展延伸,文末我们简单介绍一下 自动机 与 KMP 自动机。
有限状态自动机(Deterministic Finite Automaton,DFA)是由
- 状态集合
。 - 字符集
。 - 状态转移函数
,即 。 - 一个开始状态
。 - 一个接收的状态集合
。
组成的五元组
如果用 AC 自动机理解,状态集合就是字典树(图)的结点;字符集就是
KMP 自动机
KMP 自动机就是一个不断读入待匹配串,每次匹配时走到接受状态的 DFA。如果共有
(约定
我们发现
需要注意走到接受状态之后应该立即转移到该状态的 next。
时间和空间复杂度:
创建日期: 2018年7月11日